1 需求&设计
我们是基于开源项目去做了二次开发,更换了 logo 和 界面UI ,并新增了两个功能。
1.1 logo设计
我们以“维京龙船”的名称重新设计了logo,相关的设计思路由老三来进行补充。
1.2 新功能
1.2.1 邀请方式用户注册
为什么要用邀请码方式去做用户注册功能呢? 我觉得应该有以下几个原因:
- 1、初代版本BUG多,暂不适于大规模的去推广注册,应该先采用邀请使用的方式。
- 2、博客网站何其之多,初期采用邀请的方式吸引来注册的初代用户,基本上都是熟人,能较好的收集使用的反馈,以更好的进行项目的迭代。
- 3、防止恶意注册,占用网站资源。
那么设计的思路是什么?
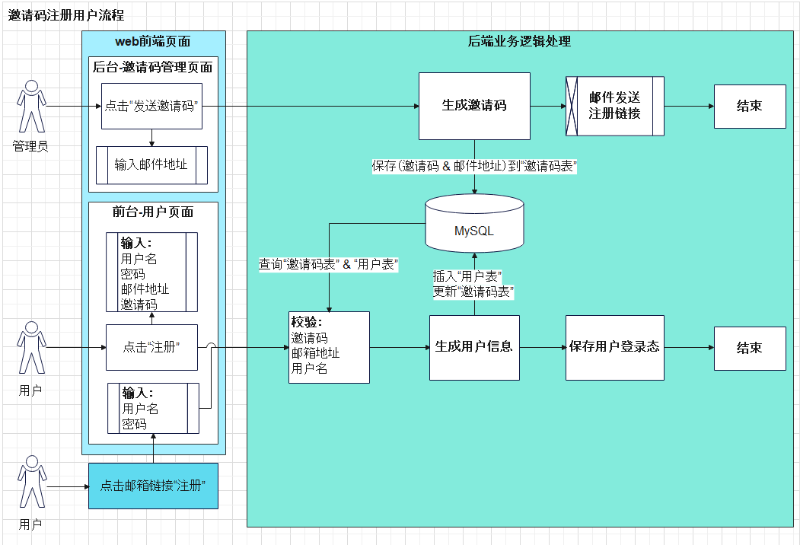
- 1、发送邀请。邀请需要用到邮件地址,把邀请的邮件发送到目标用户。邮件包含了“用户注册链接”,通过点击链接,就可以跳转到“维京龙船-博客”网站的注册页面去进行注册用户。
- 2、用户注册。用户注册页面除了必须具备的用户名、邮箱地址、密码等信息外,还有邀请码。提交注册信息时,后端业务代码会对邮箱地址和邀请码去做校验。
- 3、邀请码管理。在网站后台管理界面设计了邀请码管理,用于管理已经发送的邀请码,显示了邀请码的状态(邀请中/已接受),可进行删除邀请的操作。
1.2.2 文章发布的审核功能
文章发布的审核功能是参考CSDN(技术类博客网站)去做的。在CSDN里发布一个文章是需要审核的,审核通过后才会变更为已发布的状态,才可以在网站里展示,并可以在网站中搜索到。当然其它网站中发布内容时,也会有审核的流程。比如:bilibili。
那么问题来了,**为什么需要做审核的功能呢?**我认为应该有以下几个方面:
1、面向公众的内容,网站有这个义务去做审核。博客网站的管理者对网站上公开的内容是有责任的。如果内容不当,内容发布后造成的影响,网站的管理者是有着去不掉的责任(政府对网站的管制)。
2、对内容的品质负责。内容品质的好坏会直接影响到网站的口碑。如果内容质量参茨不齐,很难有用户再光顾。又不像CSDN那样子,数据量多,用户还是可以从中搜索到对其有价值的文章。
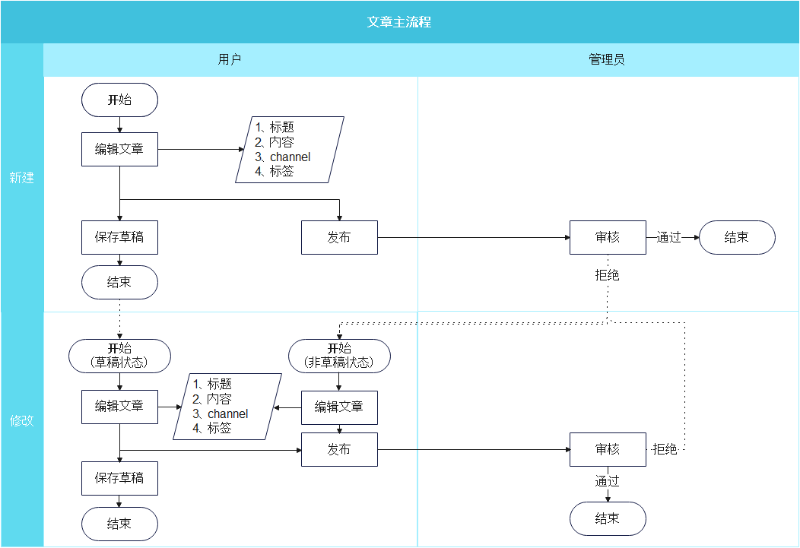
**审核功能是怎么设计的呢?**目前是这样的流程:
**1、用户新建一篇文章。**文章可以保存为草稿,也可以直接点击发布。保存为草稿的不需要审核,发布的即需要管理员来审核。审核通过就会变更为已发布状态,文章会在网站展示,并且可以被搜索到。
**2、审核不通过的文章。**用户修改后可以再发布,需要管理员再次审核。审核通过会变更为已发布状态。
**3、已发布文章的修改。**修改提交后还需要管理员审核。
2 人员安排
Rollo(我)负责了本次网站的需求梳理,具体开发,以及上线部署。
老三负责了本次网站logo的设计,以及邀请码注册和文章发布审核的页面设计。
老二、老幺参与了本次需求。
3 开发管理
在mblog工程的代码框架下进行开发,用Git做版本的管理。到代码平移到一个新建的工程后,对包名等做了适当的修改。
3.1 数据库表设计
-- 邀请码记录表
CREATE TABLE `vblog_invitation_code` (
`id` bigint(20) NOT NULL, -- 主键ID,也是邀请码
`create_time` datetime NOT NULL, -- 创建时间
`email` varchar(255) NOT NULL, -- 邮箱地址
`status` int(11) NOT NULL, -- 状态:邀请中/已接受
`type` int(11) NOT NULL, -- 类型(目前邀请只用于注册)
`update_time` datetime DEFAULT NULL, -- 更新时间
`submit_user_id` bigint(20) DEFAULT NULL, -- 提交邀请的用户ID
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.2 邀请方式用户注册
3.2.1 怎么生成邀请码?
采用的是雪花算法来生成邀请码。为什么直接不用数据库自增的ID,或者UUID等其它算法呢?
这所以用这个算法,主要是因为生成的邀请码不重复和生成全是数字,以及位数长度合适(19位数,be like:6950491587302391808)等特点。此外,这个算法的应用比较广泛,像常见的订单ID、商品ID等都比较会用雪花算法来生成。如果用数据库自增的ID,就像位数比较低,容易被枚举,不符合邀请码的使用场景。而UUID呢,随机生成的邀请码能有36个字符(be like:58a8caa4-b7c0-4319-bdc2-49fcb4a54eca),由32字16进制数字,加4个”-“组成。在数据库表中直接用作主键可能不太合适。
雪花算法生成的ID的标准结构: long类型,64bit, 包括:符号位(1bit)、时间戳(41bit)、机器码(中心节点:5bit,工作节点:5bit,共10bit)、序列号(12bit)
符号位:即正负符号,生成的ID为正数。 时间戳:取的是机器的时间(从1970年1月1日0时0分0秒0毫秒以来的毫秒值),精准到毫秒,41bit的话,可以存大概69年内的时间。 机器码:10bit的话,可分配给1024台机器。 序列号:12bit的话,即每毫秒可分配4096个ID。 计算("|"表示”或“位运算):
ID = 时间戳(向左偏移22bit)| 中心节点(向左偏移17bit)| 工作节点(向左偏移12bit)| 序列号
3.2.2 邀请注册链接的特殊字符怎么转换(比如'@'等等)?
特殊字符编码&解码
js :
encodeURI() -- 针对中文编码
ecodeURI() -- 针对中文解码
encodeURIComponent() -- 完全编码
decodeURIComponent() -- 完全解码
java :
org.apache.http.client.utils.URIBuilder -- 类来封装链接地址
3.2.3 怎么发送邮件?
首先得要先整一个邮件模板(.html的),然后可以直接用工程内集成的freemark来动态的插入一些数据。
邮件的发送,需要邮箱开通 SMTP 服务。如下图
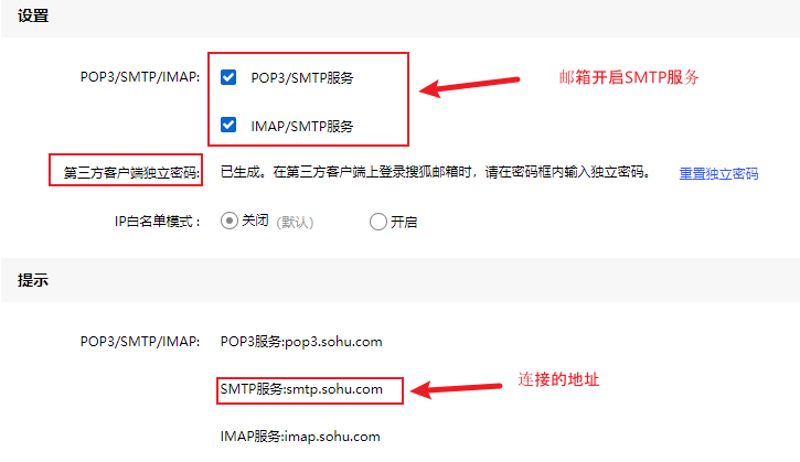
工程中引用了oh-my-email 的jar包。是一个不可信的jar包,因为它没有封装好对 javax.mail.Transport 的调用,所以调试时就没调通。好在我们可以参考它并修复一下(能用总比自己从0开始强)。
javax.mail.Transport 其本质与 telnet 发送邮件方式类似。
步骤:
- auth login -- 认证
- from -- 声明从哪发出
- to -- 声明发到哪里
- data -- 发送的数据
原理就像是用 telnet 发送邮件(参考: https://www.jianshu.com/p/11f5aa0bd5d3 ),cmd中敲命令如下:
telnet smtp.sohu.com 25
auth login
// 账号base64加密字符
// 密码base64加密字符
mail from:youremail@sohu.com
rcpt to:target@qq.com
data
to: somebody
from: rollo
subject: this a test
hello world
.
3.3 文章发布的审核
3.3.1 一些业务逻辑上的问题
- 如果一篇文章已经发布过了,再次进行修改时应该如何保存?
如果考虑用户可以把修改保存为草稿的情况,那么就得加临时表。(没有必要)
如果原来非草稿状态的文章,修改后发布就得审核,期间用户也可以再编辑。(CSDN也是这样做的)
- 只有草稿状态的文章,修改时才可以保存为草稿
3.3.2 遇到的技术上的问题
1、增删除文章事件处理报错: 缓存中找不到 articleCaches 的问题
-
原因: 修改了 @CacheEvict(value = {Consts.CACHE_USER, Consts.CACHE_ARTICLE}, allEntries = true) 注解的 Consts.CACHE_ARTICLE 的值,但没有同步修改缓存配置文件 ehcache.xml 里对应的缓存 name,从而导致推送事件时报错。
-
归类:缓存组件Ehcache的使用
2、方法的代码里没有看到有持久化的代码,文章的修改是怎么保存到数据库里面的呢?
- 参考: 当使用了实体类set属性的时候,但是我们并没有持久化,却自动保存到数据库了。( https://blog.csdn.net/chenyidong521/article/details/78854410 )
- 原因: Hibernate分为三种基本的状态:游离态、自由态(临时状态)、持久态。持久化状态:与session关联并且和在数据库有数据,已经持久化了并且在数据库的缓存当中了。
3、字符集问题,导致保存数据库报错
-
Caused by: java.sql.SQLException: Incorrect string value: '\xE4\xBD\xA0\xE5\xA5\xBD' for column 'title' at row 1
-
解决:
-- 修改表的字符集
ALTER TABLE vblog_article DEFAULT CHARACTER SET utf8mb4;
-- 修改字段的字符集
ALTER TABLE vblog_article CHANGE title title VARCHAR(100) CHARACTER SET utf8 COLLATE utf8_general_ci;
- 根源:在创建数据库实例的时候,就应该给定正确的默认字符集。
CREATE DATABASE `vblog` /*!40100 DEFAULT CHARACTER SET utf8mb4 */
小结
- 本次开发是在边开发边梳理的。一个是对原有功能(文章发布流程)还没有太熟悉,时间充裕情况下应该把流程梳理清楚,画个流程图。业务逻辑的梳理应该在敲代码之前,应该尽可能的梳理清楚,这样开发才能更高效。
- 对工程现有的组件还不太熟悉。比如Encache这个用来做缓存的组件,再比如用来做搜索的Lucene(其实集成到 hibernet 上了,其原理不熟悉,就难以去做优化和改造)。
4 集成部署
部署环境用的是阿里云的 ECS 服务器,直接运行构造好的 jar 包。
- 操作系统: Ubuntu 20.04 64位
- 版本管理: Git
- 项目构建: Maven
- 反向代理: Nginx(配置反向代理8080端口)
遇到的一些问题:
- git 的 .gitignore 文件配置的问题。本地调时会在工程的目录下生成一些文件夹来存储日志文件,上传的图片等等,git不应该把这些目录纳入版本管理,所以在.gitignore文件下配置了这些目录的名称。但不巧的是代码包路径有同名的文件夹,导致同名文件夹下的代码没有纳入到版本管理里来,然后在推代码的时候,就漏了。
- mvn 打包如何指定环境?如用dev的环境并跳过test: mvn clean package -P dev -Dmaven.test.skip=true
5 待处理的问题
- 数据库备份问题。是否可以采用主从模式?
- 多媒体文件备份存储问题。单独分拆出一个多媒体文件存储的应用?
- 日志的打印(有用日志信息偏少)及日志文件备份问题。
6 下个迭代的展望
业务上
迭代方向为IT从业人员(产品经理 / UI / 前端开发 / 后端开发 / 测试 / 运维)提供持续学习的博客社区平台。
为什么不专注于某个岗位的呢?我觉得那没有必要,因为这样的话会是“只见树木,不见森林”。早期的IT从业人员,其实会兼顾了现在的多个角色,即是产品经理和UI、也是具体的开发,测试和运维的工作就更不必说了。就比如说我们可以对后端的开发很熟悉很专长,但对整个链条(各个技术栈)也很熟悉,那么这个能力就会比较完整。
技术上
当前的博客网站属于典型的单体应用,就是所有的都放在了同一个应用里了。
下一迭代项目应该采用分布式架构去进行迭代。
注意:本文归作者所有,未经作者允许,不得转载
