经过几个月对AI大模型的接触和了解,不管是国内还是国外的API接口都采用了统计输入输出文本token的方式来计算费用。比如调用OpenAI的gpt-3.5-turbo-16k模型的接口,计算token的公式是:
total(总的) tokens = prompt(输入的) tokens + completion(输出的) tokens
我们拿到这个总的tokens就知道,每次这个接口花了什么钱了。
1 tokens计算工具网页
openai提供了线上计算tokens的工具网页,把字符串贴上去就可以得到对应的token数。
openai的线上计算tokens的工具网页(gpt3模型的): https://platform.openai.com/tokenizer
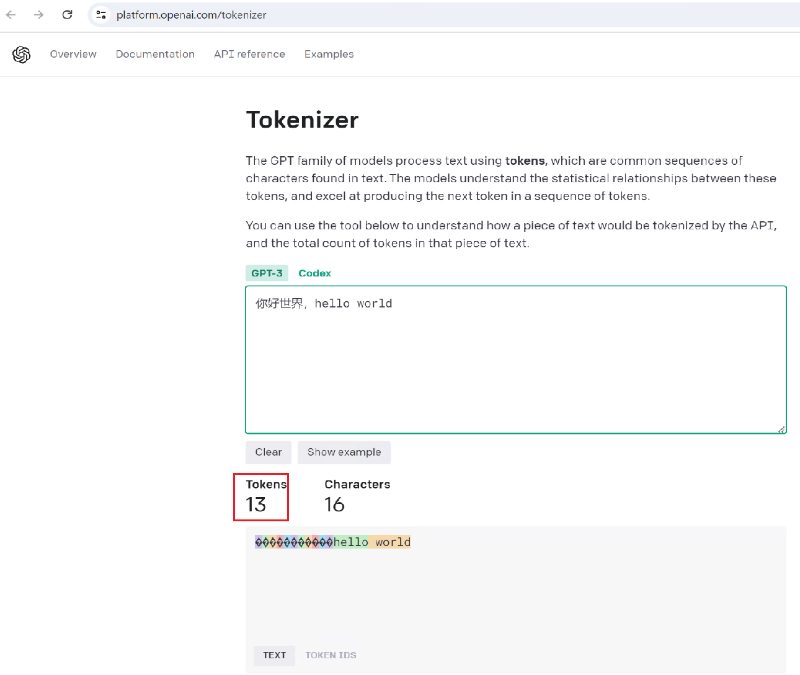
由上图,我们可以看到一个英文单词,可以对应一个token数,但一个中文字符,可能对应多个token数。
2 tiktoken来计算tokens
那么具体是怎么计算的呢?有没有现成的算法提供出来呢? 通过一翻查找,总算在OpenAI在github上面的文档中找到。
文档链接:
https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
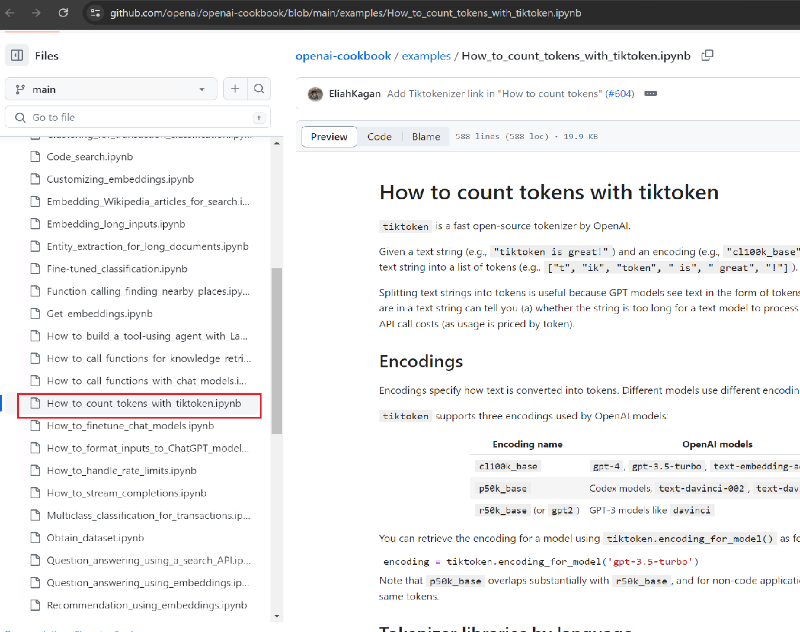
对于token的计算,还要考虑具体的大模型,因为OpenAI他家各个模型间对文本的编码是有区别的,所以同样的文本计算出来的token数会有所区别。
从上图可知,我们常用的gpt-4和gpt-3.5-turbo用的是cl100k_base编码,而之前的gpt2和gpt-3用的编码叫r50k_base。
对于cl100k_base和p50k_base编码的:
- Python: tiktoken
- .NET / C#: SharpToken, TiktokenSharp
- Java: jtokkit
- Golang: tiktoken-go
我用的是java来开发,接下来就用 jtokkit 来展开吧
2.1 引入 jtokkit 依赖
<dependency>
<groupId>com.knuddels</groupId>
<artifactId>jtokkit</artifactId>
<version>0.6.1</version>
</dependency>
2.2 计算token数
// 创建实例
EncodingRegistry registry = Encodings.newDefaultEncodingRegistry();
// 指定 CL100K_BASE 编码
Encoding enc = registry.getEncoding(EncodingType.CL100K_BASE);
// 进行编码
List<Integer> encoded = enc.encode("你好世界,hello world");
System.out.println(encoded);
// [57668, 53901, 3574, 244, 98220, 3922, 15339, 1917]
// 输出编码后的集合大小(也就是token数)
System.out.print(encoded.size());// 8
输出的token数为8。这是不是和上面网页上计算的不一致呀?!没关系,只要你足够细心,你会发现上面的用的GPT-3模型,所以只要我们改一下编码就一样了:
Encoding enc = registry.getEncoding(EncodingType.R50K_BASE);
3 总结
- 不同的AI大模型对文本的编码方式会不同。
- 还是得看官网的文档。
参考: 知乎:ChatGPT如何计算token数?https://www.zhihu.com/question/594159910
注意:本文归作者所有,未经作者允许,不得转载
