1 为什么需要CPU缓存一致性协议?
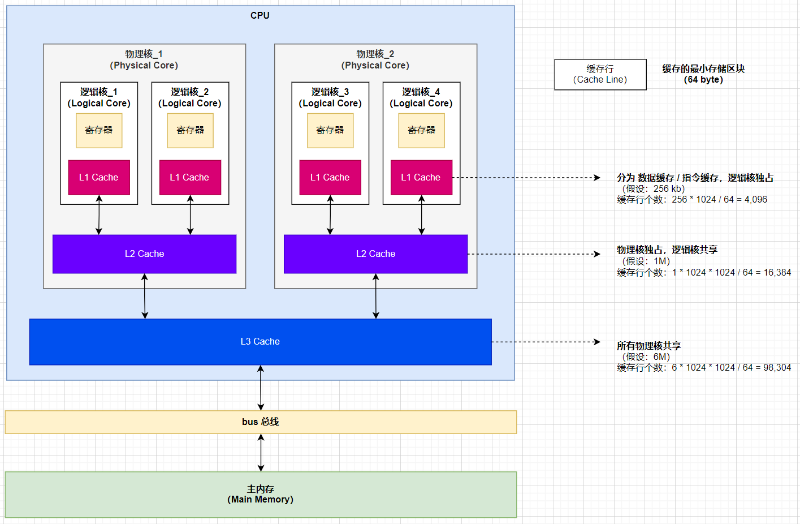
为了解决CPU处理速度远快于内存的读写,我们为了优化读写,引入的CPU的高速缓存, 每个CPU的每个核都有自己的缓存,用于加速对内存的访问。 然而,当CPU的多个核同时访问相同的内存位置时,可能会出现缓存的数据不一致问题。
 ]
]
2 MESI协议
MESI协议是一种基于失效的缓存一致性协议,是支持写回(write-back)缓存的最常用协议。
MESI协议是一组规则和协议,定义了多个处理器(CPU)如何协同工作,
确保多个处理器(CPU)之间的缓存(一级缓存)中的数据保持一致。
CPU缓存的最小存储区块是缓存行(Cache line),MESI协议是就在缓存行的维度展开的。
2.1 缓存行(Cache line) 4 种状态
- 已修改 (Modified, M)
- 缓存行是脏的(dirty),与主存的值不同。
- 如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S)
- 独占 (Exclusive, E)
- 缓存行只在当前缓存中,但是干净的(clean)–缓存数据同于主存数据。
- 当别的缓存读取它时,状态变为共享(S);
- 当前写数据时,变为已修改状态(M)。
- 共享 (Shared, S)
- 缓存行也存在于其它缓存中且是干净的。
- 缓存行可以在任意时刻抛弃。
- 无效 (Invalid, I)
- 缓存行是无效的。
任意一对缓存,对应缓存行的相容关系:
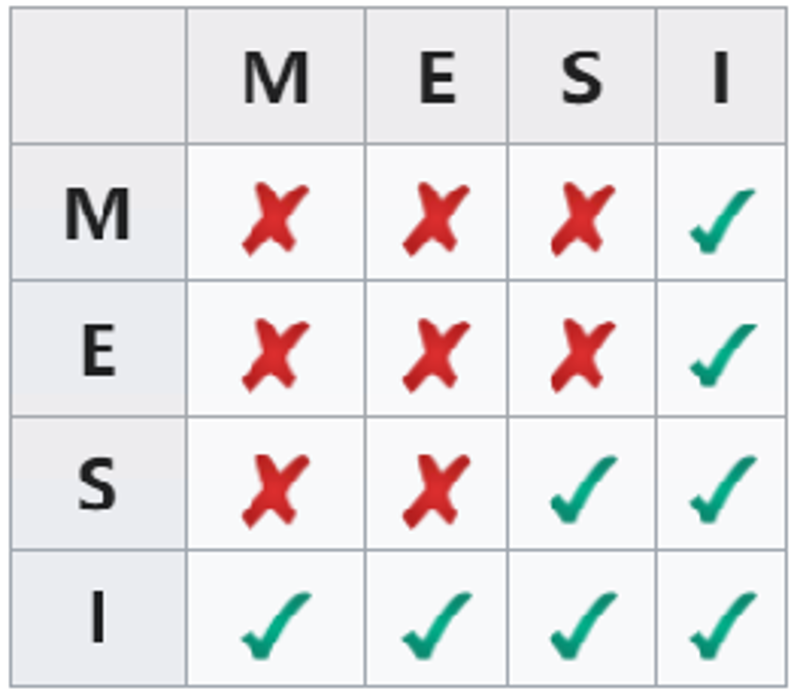
如上图,示例:当一缓存中某缓存行标记为M(已修改),在其它缓存中的数据副本被标记为I(无效)。
2.2 缓存行的状态转换
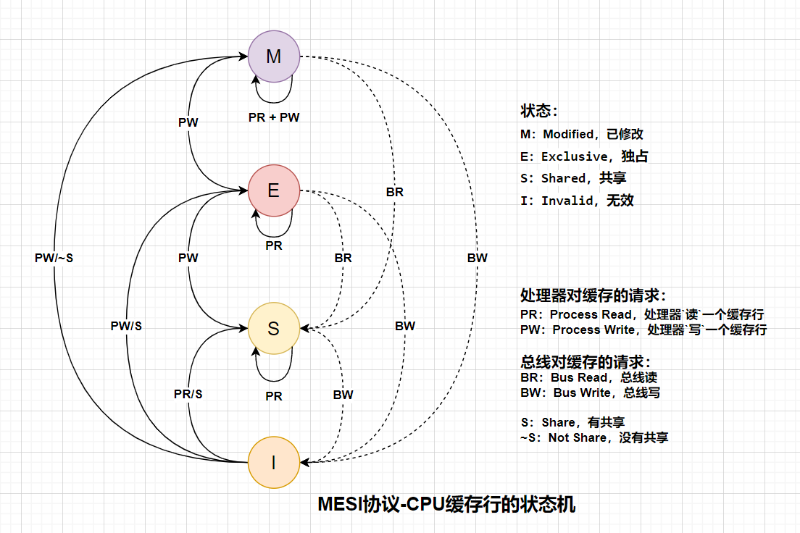
处理器对缓存的请求:
- PR:Process Read,处理器
读一个缓存行 - PW:Process Write,处理器
写一个缓存行
总线对缓存的请求:
- BR:Bus Read,总线读
- BW:Bus Write,总线写
缓存行情况:
- S:Share,有共享缓存
- ~S:Not Share,没有共享缓存
MESI协议要求在缓存不命中(miss)且缓存行在另一个缓存时,允许缓存到缓存的数据复制。
假设:现有两个处理器A、B,还有共享变量 X,转换过程如下:
先读取:
-
处理器A先从主存中读取了 X,这时是独享状态(E);
-
处理器B也要读取,通过总线地址冲突检测到A的缓存有X这个变量,就向A请这个值,于是X就变成了共享状(S);
再修改:
- 处理器B要修改X,通过总线发出失效命令,并等待A的ACK确认; A缓存中的X变成失效状态(I),本地缓存的 X变为独享状态(E)后才可以修改,并把最值刷新到主存;
重复修改:
- 处理器B再修改一次了X后,状态就变成了修改状态(M);
最后再读一次:
- 处理器A又要读取X时,B把X同步给A,并刷新回主存,X 此时变为共享状态(S)。
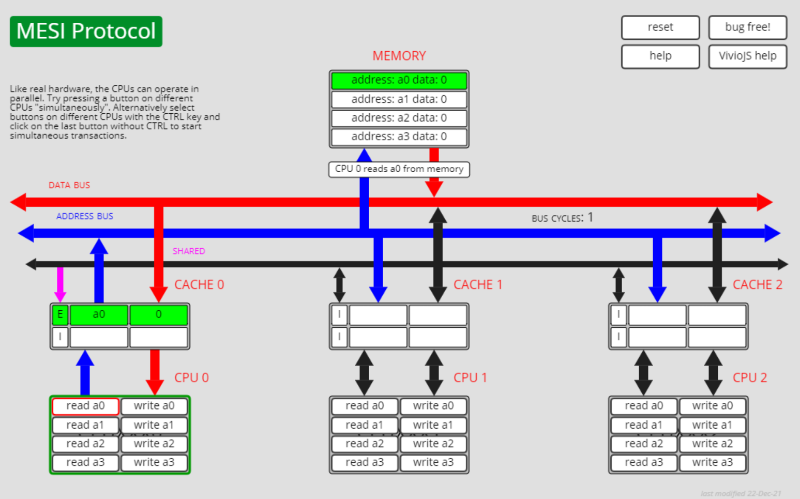
体验MESI协议-读写共享变量【确实可以帮忙理解】 https://www.scss.tcd.ie/Jeremy.Jones/vivio/caches/MESIHelp.htm
3 MESI协议的优化
为什么要对MESI协议做优化呢?
因为在MESI协议中进行写操作时,会存在CPU切换状态阻塞解决的问题。
当处理器要写一个缓存行时,会发出总线写的消息,然后CPU要等待其它缓存收到消息 & 把对应的缓存行状态修改为失效(I),这个过程对CPU是比较耗时。
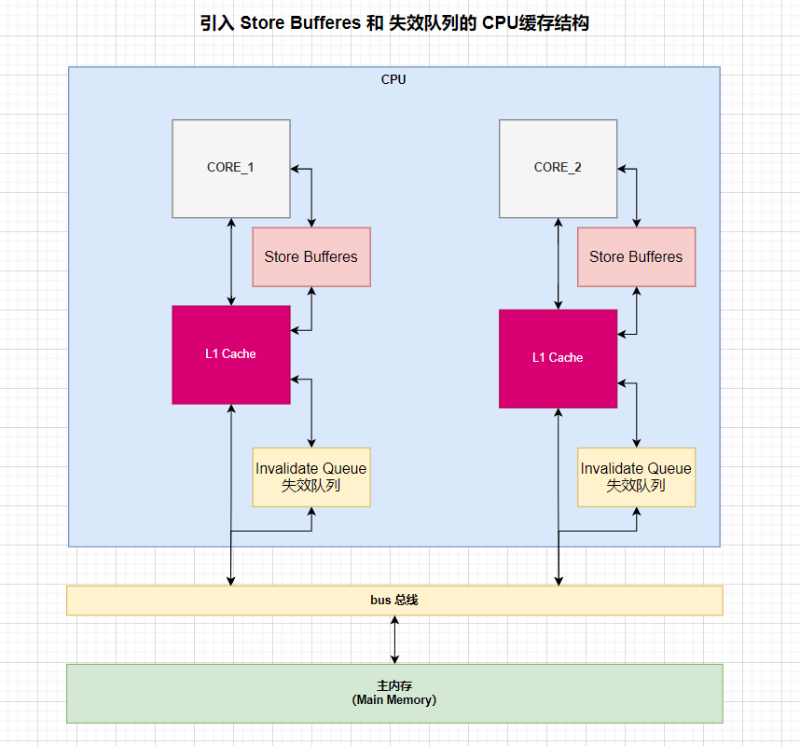
3.1 Store Bufferes
CPU切换状态阻塞解决方案--Store缓存区。
处理器把它想要写入到主存的值写Store Bufferes,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
Store Bufferes的风险:
- 指令重排序的问题。因为还没收到其它缓存的失效确认,被修改的变量还存放在
Store Bufferes,相当于没执行完,但原先在后面的指令可能已经执行完毕,这就会导致指令重排序。
3.2 失效队列(Invalidate Queue)
失效队列(Invalidate Queue)的引入,是为了加快失效确认的响应。
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送。
- Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。
参考:
- MESI协议 https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE
注意:本文归作者所有,未经作者允许,不得转载
