1 环境准备
寄主机器系统: windows 11
wls的linux发行版: Ubuntu 22.04.5 LTS
linux内核版本: Linux 6.6.87.2-microsoft-standard-WSL2
安装 docker 和 docker-compose
sudo apt install docker
sudo apt install docker-compose
指定docker的配置,修改 /etc/docker/daemon.json 文件
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.1ms.run"
],
"experimental": false,
"features": {
"buildkit": true
},
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
builder.gc.defaultKeepStorage参数指定默认的存储大小,以防止Docker容器的日志文件无限扩大。registry-mirrors参数指定了docker镜像源(国内访问官方docker镜像源受限)。runtimes.nvidia.path参数指定了docker容器调用nvidia的GPU的信息。features.buildkit参数指定BuildKit为默认构建引擎。experimental参数是实验性功能的开关。
2 Docker Compose方式部署 dify
参考: https://legacy-docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
# 拉取 dify 代码(不方便用github,故用gitee平台)
git clone https://gitee.com/dify_ai/dify.git
# 拉取所有的 tags (以便切换到目标的tag)
git fetch --all --tags
# 进入到docker目录
cd dify/docker
# 设置环境变量文件
cp .env.example .env
# 启动docker容器
docker compose up -d
访问dify: http://localhost:80
3 Docker方式部署 Ollama
参考: https://zhuanlan.zhihu.com/p/1902057589019251082
官方文档: https://github.com/ollama/ollama/blob/main/docs/docker.md
拉取ollama的docker镜像
sudo docker pull ollama/ollama
3.1 CPU模式
CPU only,即只使用CPU来跑大模型的模式。
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
至此,成功执行完上面的命令就可正常使用ollama来运行大模型了。
3.2 GPU模式
CPU由于核数限制,并行计算能力不高。用GPU即可以大大提高大模型的运行速度。
Nvidia GPU
Install the NVIDIA Container Toolkit. https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html#installation
WLS方式的安装对应CUDA,只要windows已经安装对应驱动就行) https://docs.nvidia.com/cuda/wsl-user-guide/index.html
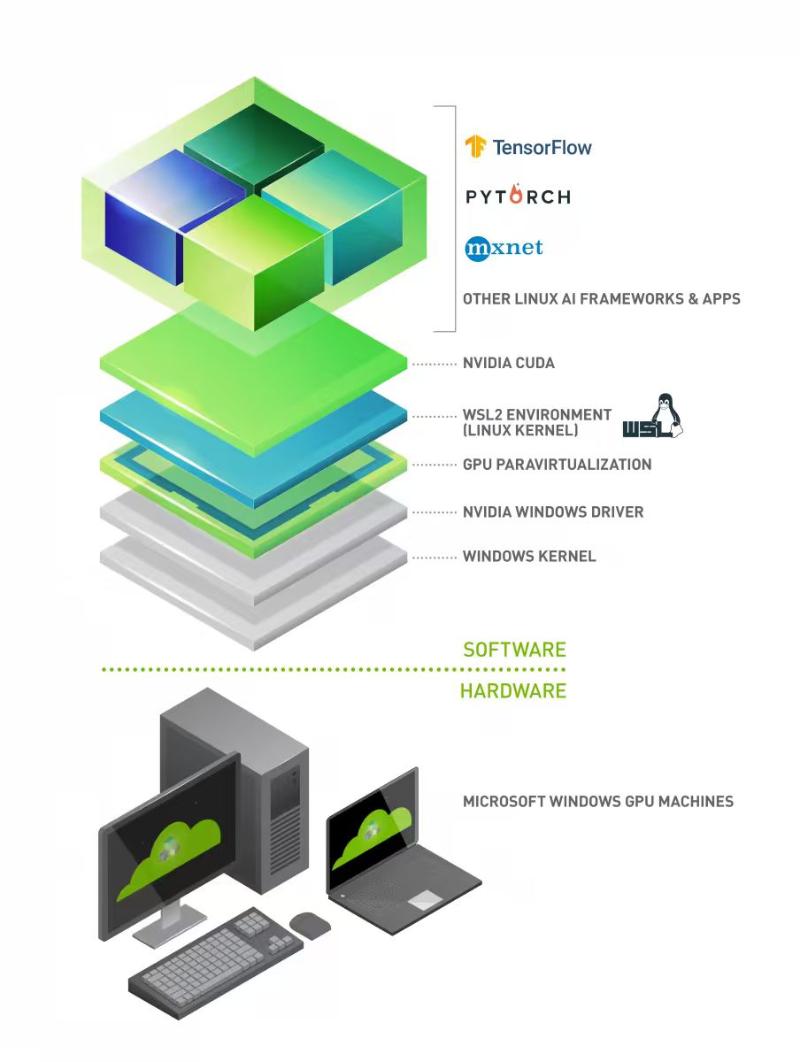
CUDA Toolkit 13.0 Downloads https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=WSL-Ubuntu&target_version=2.0&target_type=deb_network
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-13-0
安装docker调用nvidia GPU的工具:
# 安装工具
sudo apt-get install -y nvidia-container-toolkit
# 增加配置
sudo nvidia-ctk runtime configure --runtime=docker
# 重启docker服务
sudo systemctl restart docker
启动ollama的docker容器:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
4 用 Ollama 来本地运行大模型
ollama 可以运行的模型: https://ollama.com/search
运行一个模型:
docker exec -it ollama ollama run deepseek-r1:8b
5 其它
5.1 打通 dify 和 ollama 容器的网络
# 查看网络列表
sudo docker network ls
# 查看 docker_default 网络的明细
sudo docker network inspect docker_default
# ollama 容器加入 docker_default 网络
docker network connect docker_default ollama
5.2 升级 WSL 里的 ubuntu 系统版本
【解决 docker-compose 版本过低,导致 ${} 的语法无法解析的问题】
from 18.04 ==> 20.04 ==> Ubuntu 22.04.5 LTS
参考: ubuntu18.04 升级到ubuntu22.04版本 https://blog.csdn.net/sunyuhua_keyboard/article/details/135073275
# 更新当前系统
sudo apt update
sudo apt upgrade
sudo apt dist-upgrade
# 安装更新管理器核心
sudo apt install update-manager-core
# 配置升级设置
sudo vim /etc/update-manager/release-upgrades
# 修改Prompt配置 ==> Prompt=lts
# 开始升级
sudo do-release-upgrade
5.3 迁移 WSL 的发行版的物理存储位置
参考: WSL和Docker位置迁移 https://zhuanlan.zhihu.com/p/1928029354618773715
停止WSL(管理员权限打开PowerShell): wsl --shutdown
导出现有发行版到目标盘(如D盘)
# 使用此命令查看当前的发行版:
wsl -l -v
# 使用此命令导出
wsl --export <发行版名称> D:\wsl-backup.tar
# 示例(Ubuntu迁移):
wsl --export Ubuntu D:\ubuntu.tar
# 注销原发行版:
wsl --unregister <发行版名称>
# 示例:wsl --unregister Ubuntu
# 导入到新位置:
wsl --import <新发行版名称> D:\WSL\Ubuntu D:\ubuntu.tar
# 导出完成后可删除备份的压缩文件,如D:\ubuntu.tar
# 迁移后打开会发现是Root权限
5.4 Ollama由GPU模式降为CPU模式
现象:从任务管理器上观察 ollama跑模型,一开始有用 GPU,后面直接只用 CPU。
模型大了,超过 GPU 的显存,那么就会自动降为 CPU 模式。
比如,运行了deepseek-r1:8b模型,这个模型的大小为 5.2GB,而我们的GPU的显存为 6GB,这很明显是可以运行的。但随着多轮问题,产生的数据,让模型运行占用的大小超过了 6GB,那么Ollama就会降为CPU模式来运行。
# 进入ollama的docker容器内
docker exec -it ollama /bin/bash
# 查看模型运行情况
ollama ps
设置让模型跑在 GPU 上?!
变量名:OLLAMA_GPU_LAYER
变量值:cuda
nvidia-smi -L,即可查看GPU的UUID
变量名:CUDA_VISIBLE_DEVICES
变量值:GPU的UUID(按编号有时找不到,所以使用UUID)
注意:本文归作者所有,未经作者允许,不得转载
